Model pruning is a compression technique, that aims to remove redundant components without significantly compromising the model’s performance or accuracy. This process facilitates efficient deployment of complex models by making them smaller and faster.
Pruning is a hardware-agnostic compression approach. Unlike some other compression approaches such as quantisation, models resulting from structured pruning can be deployed on any modern GPU with similar performance gains. Moreover, pruning can be part of a sophisticated compression pipeline that incorporates other techniques such as quantisation and efficient fine-tuning (e.g. LoRA, QLoRA), which can lead to higher compression and efficiency levels.
In this article, we will cover some insights from our two papers about Iterative Layer Pruning at IWSLT 2025 [1] and WMT 2025 [2].
Iterative Layer Pruning
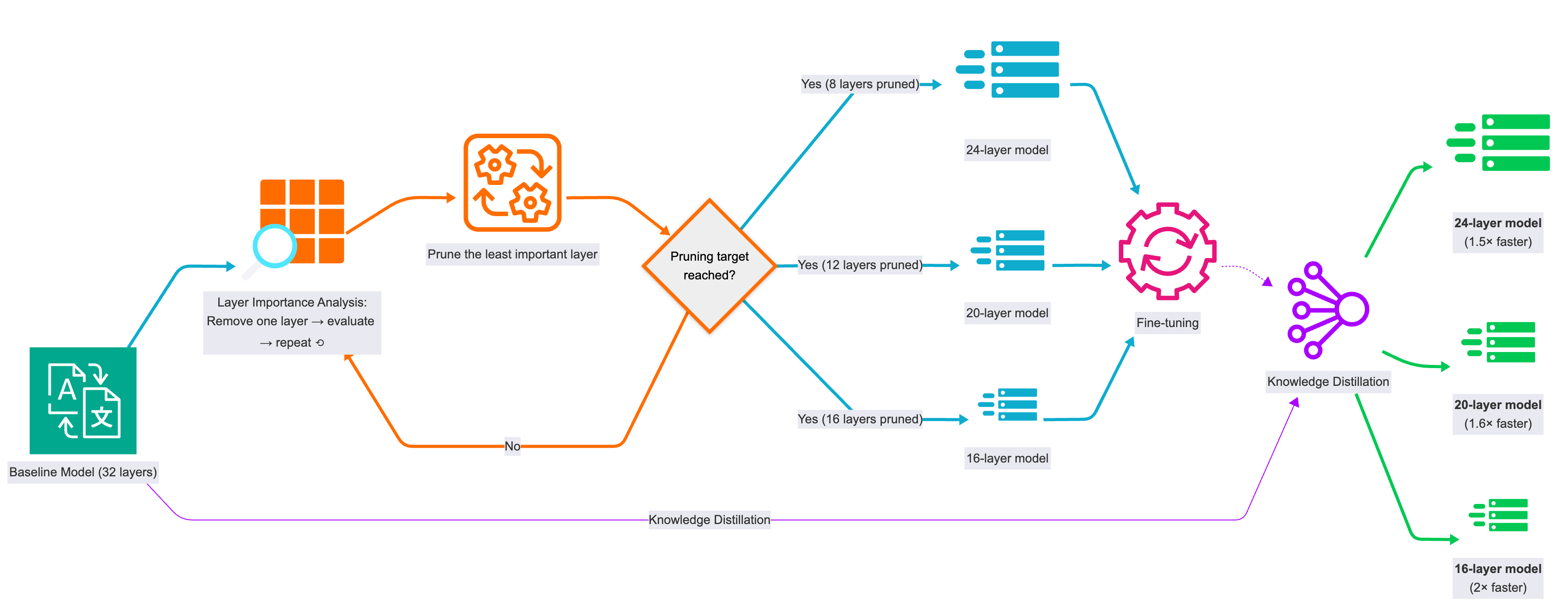
The process of Iterative Layer Pruning involves incrementally identifying and removing layers with minimal contribution to translation or generation quality, one layer at a time. The pruning process is usually followed by fine-tuning the resulting models on relevant training data to restore the translation quality. Moreover, knowledge distillation data from the baseline (teacher) model can be used to help the pruned (student) model to reach the quality of the teacher model.
Layer Importance Evaluation
We conduct layer importance evaluation by measuring translation performance without each layer. The process is as follows:
- Remove one layer of the model.
- Evaluate the model (chrF++).
- Repeat for the rest of the layers.
- Prune the least important layer (best chrF++ without it).
- Repeat #1 to #4 until reaching the pruning target.
Evaluation Results
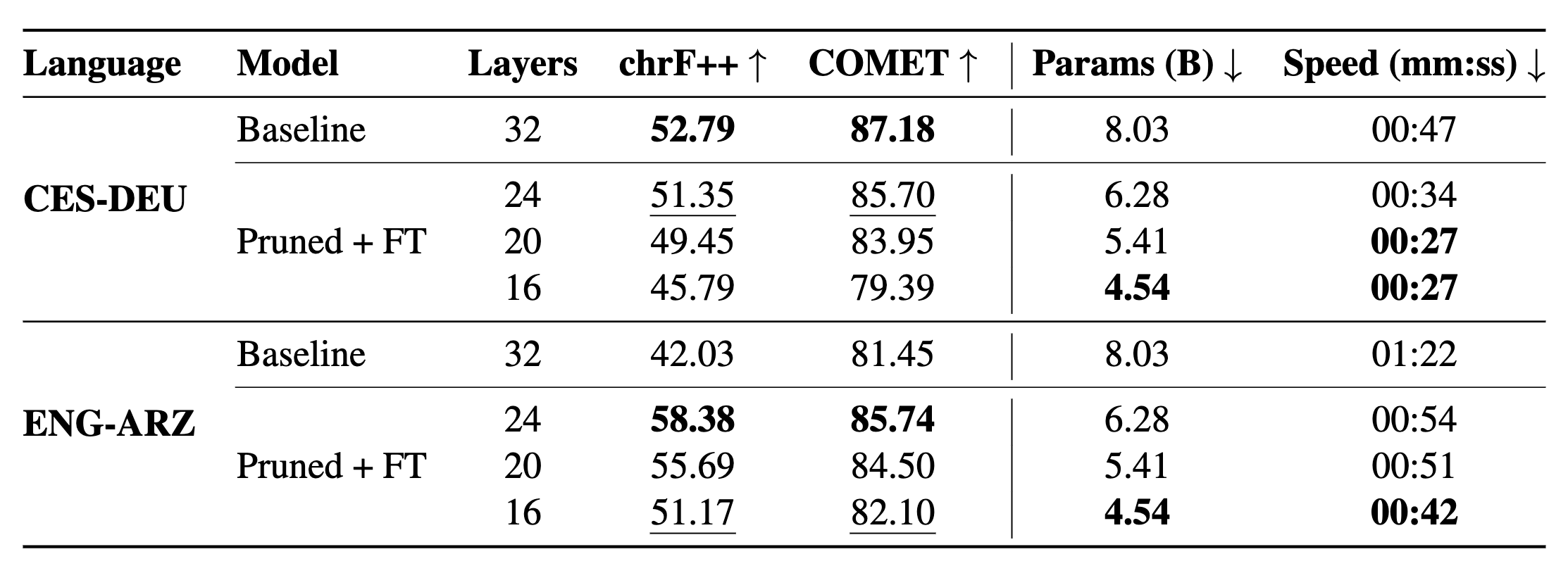
For translation from Czech to German (CES-DEU), pruning 8 layers and then fine-tuning the resulting model retains 98% of the translation quality (as measured by COMET), while achieving considerable speedup gains. Interestingly, for translation from English to Egyptian Arabic (ENG-ARZ), the model resulting from pruning up to 16 layers and then fine-tuning outperforms the Aya-Expanse-8B baseline for this language pair. Pruned models achieve up to ~2× speedup.
Knowledge Distillation
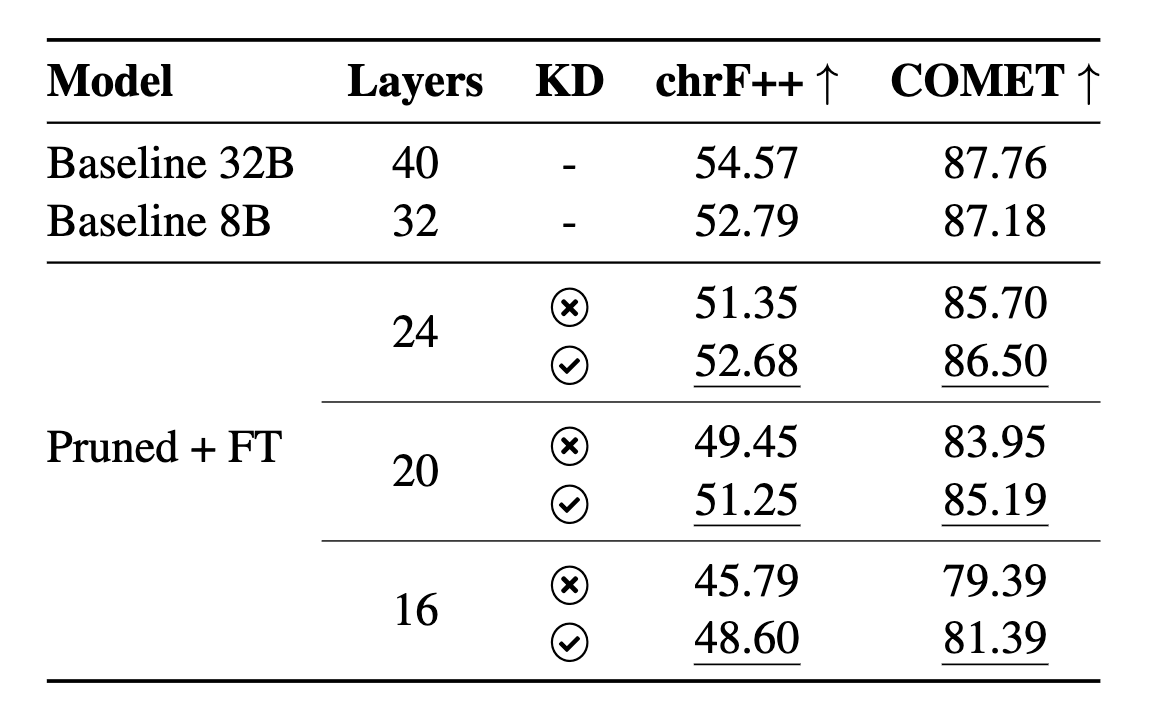
Knowledge Distillation aims at transferring knowledge from a larger model (teacher) to a smaller one (student). In “sequence-level” knowledge distillation, the student model is trained to generate sequences that match the teacher’s sequence outputs. Fine-tuning the pruned models on a combination of authentic and synthetic data (from Aya-Expanse-32B) improved the Czech to German (CES-DEU) translation quality, with the 24-layer pruned model nearly matching the performance of the Aya-Expanse-8B baseline.
Further performance gains
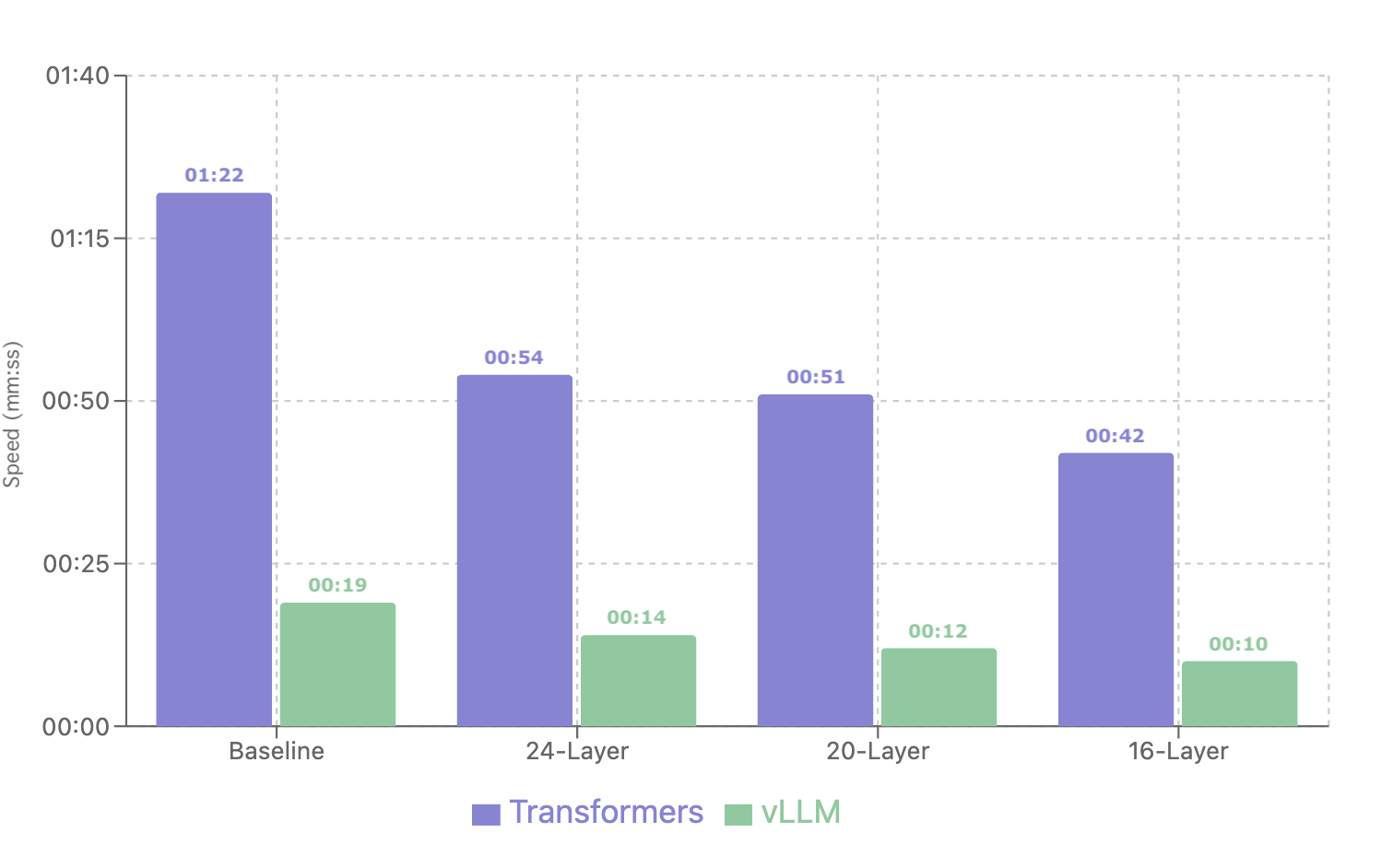
It is highly recommended to use an efficient inference engine such as vLLM, which outperforms inference with the Transformers framework. In both cases, pruned models demonstrate up to ~2× speedup.
Moreover, you can quantise the pruned models for further compression. For example, in our IWSLT 2025 paper, we applied QLoRA after pruning the models. However, notice that low-precision quantisation (e.g. 4-bit and 8-bit) requires special hardware (e.g. H100 or H200) to observe performance gains.
Questions and Answers
- Q. Why iterative layer pruning instead of random or middle layer pruning?
- A. Iterative layer pruning relies on layer importance analysis. Hence, only the layers with minimal contribution to the output quality can be removed. In our experiments, iterative layer pruning achieves better results than middle layer pruning.
- Q. Can we prune other parts of the model other than layers?
- A. There are two types of pruning, structured pruning and unstructured pruning. In structured pruning, you can remove whole layers, attention heads, or other entire computational blocks, while in unstructured pruning, you can remove individual weights from a neural network. While unstructured pruning can achieve higher compression rates, it requires specialised hardware for efficient deployment. On the contrary, models resulting from structure pruning can be deployed on standards GPUs.
- Q. Is it better to fine-tune the baseline model before pruning?
- A. If your task, domain, or language is very different from the distribution of the baseline model, it is better to fine-tune the baseline model first. Otherwise, you can prune the baseline directly. On the contrary, fine-tuning after pruning is always required to restore the quality of the baseline model.
- Q. Can we fine-tune after each layer pruning step?
- A. We experimented with both fine-tuning after each layer pruning step, and after a number of pruned layers. In both cases, there was no difference than just fine-tuning once after the end of the pruning process. This might be because of overfitting resulted from several fine-tuning passes.
- Q. Can the same approach be applied to encoder-decoder models?
- A. Yes, we applied this iterative layer pruning approach to both a decoder-only model, Aya-Expanse, and an encoder-decoder model, Qwen2-Audio. However, for encoder-decoder models, we observed that only pruning the decoder leads to better overall performance.
GitHub Repository
References
- Efficient Speech Translation through Model Compression and Knowledge Distillation (Moslem, IWSLT 2025)
- Iterative Layer Pruning for Efficient Translation Inference (Moslem et al., WMT 2025)