In-domain data scarcity is common in translation settings, due to the lack of specialized datasets and terminology, or inconsistency and inaccuracy of available in-domain translations. You might be familiar to such situation when there is a big translation project, but there is only a tiny in-domain translation memory, or no translation memory at all. In the absence of sufficient domain-specific data required to fine-tune machine translation (MT) systems, adhering to the domain terminology and client’s style can be challenging. Recently, there has been a considerable advancement in training large language models, not only for English, but also for diverse languages. Among autoregressive language models, trained to predict the next word in a sequence, are BLOOM, GPT-3, and GPT-J. The question is: can we use these large language models to generate more domain-specific bilingual data?
Method
Interestingly, when you feed such large language models with an in-domain sentence, they can generate more synthetic sentences, that simulate the domain and linguistic characteristics of the authentic sentence. In the research “Domain-Specific Text Generation for Machine Translation” (Moslem et al., 2022), we investigated the feasibility of this domain-specific text generation technique, when either no or limited bilingual in-domain dataset is available. We proposed a novel approach to domain adaptation leveraging state-of-the-art pre-trained language models to generate huge amounts of synthetic bilingual in-domain data with the goal of improving translation of in-domain texts. The process can be summarised in three simple steps:
1. Text generation (target)
Generate target-side synthetic sentences using a large pre-trained language model.
When there is a small in-domain translation memory, you can use each target sentence as a prompt to generate text, that simulates the domain characteristics of the authentic in-domain data. If there is no translation memory at all, you can first forward-translate the source text to be translated, or a portion of it, using the baseline MT model.
2. Back-translation (source)
Back-translate the synthetic target-side sentences into source language.
Combining the idea of in-domain text generation with back-translation, you can generate huge amounts of synthetic bilingual in-domain data, for both use cases.
3. Mixed fine-tuning
Fine-tune the baseline model, on a mix of synthetic and authentic data.
Finally, the baseline MT model should be fine-tuned using a combination of the synthetic bilingual in-domain dataset and a randomly sampled section of the original generic dataset.
Target Text Generation
This code snippet shows how to load the GPT-J language model. You can use some efficient loading techniques such float16 and low_cpu_mem_usage.
from transformers import GPTJForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B", padding_side="left")
tokenizer.pad_token = tokenizer.eos_token
model = GPTJForCausalLM.from_pretrained("EleutherAI/gpt-j-6B",
revision="float16",
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
cache_dir = "models_cache/",
pad_token_id=tokenizer.eos_token_id)
model = model.half()
model = model.to("cuda")
Afterwards, you can use each target segment in the authentic in-domain dataset, to generate synthetic in-domain text. We use top-K and top-p sampling to generate diverse text sequences. Here, we set num_return_sequences to generate 5 sequences. Each sequence might include multiple sentences. You can then split these text sequences into several sentences using any sentence splitter.
target_segment = "I am an example sentence that talks about something very specialized!"
input_ids = tokenizer(target_segment, add_special_tokens=True, return_tensors="pt").input_ids.to("cuda")
sample_outputs = model.generate(input_ids,
do_sample=True,
max_length=300,
top_k=50,
top_p=0.95,
num_return_sequences=5,
early_stopping=True)
generated_text = tokenizer.batch_decode(sample_outputs, skip_special_tokens=True)
The quality of the language model is important. Here, you can see examples of generated text, that is both linguistically correct, and factually accurate.
In March 2020, India ordered the countrywide shut down of all non-essential economic activities due to the spreading COVID-19 pandemic.
While the overall worldwide economic impact of COVID-19 will only be realized through the end of 2020 and the recovery phase in 2021, it is clear that certain parts of the world have been severely impacted.
Sometimes, the generated text can be linguistically correct; however, numbers or names might be inaccurate.
Antiviral drugs are approved for pregnant women and should be considered for children younger than XX years, although some are still being investigated.
Scientists have found some species of unicorn in Amazon rainforests.
If there are only small mistakes, the generated synthetic data can be still used. Obviously, the better the quality of the text generated by the language model, the better the quality we can expect when fine-tuning the baseline MT model on this synthetic data.
Back-Translation
Now, we have the target side of our new in-domain dataset. To generate the source side, use back-translation, into the other language direction. For back-translation, you can either train another MT model yourself, or use pre-trained models such as OPUS models. Optionally, you can convert OPUS models to the CTranslate2 formate with quantisation to enhance efficiency.
Basically, both the source and target sides of our new large in-domain dataset, consist of synthetic data. The target side is generated by a language model, while the source text is generated by back-translation, in the other language direction.
Mixed Fine-Tuning
Now, it’s time to apply mixed fine-tuning to the baseline model.
In other words, continue training our baseline model on a mix of (a) the synthetic bilingual in-domain dataset we obtained from the two previous steps, and (b) a randomly sampled portion of the original generic dataset. In our experiments, we oversampled the synthetic in-domain dataset, by a 9x ratio.
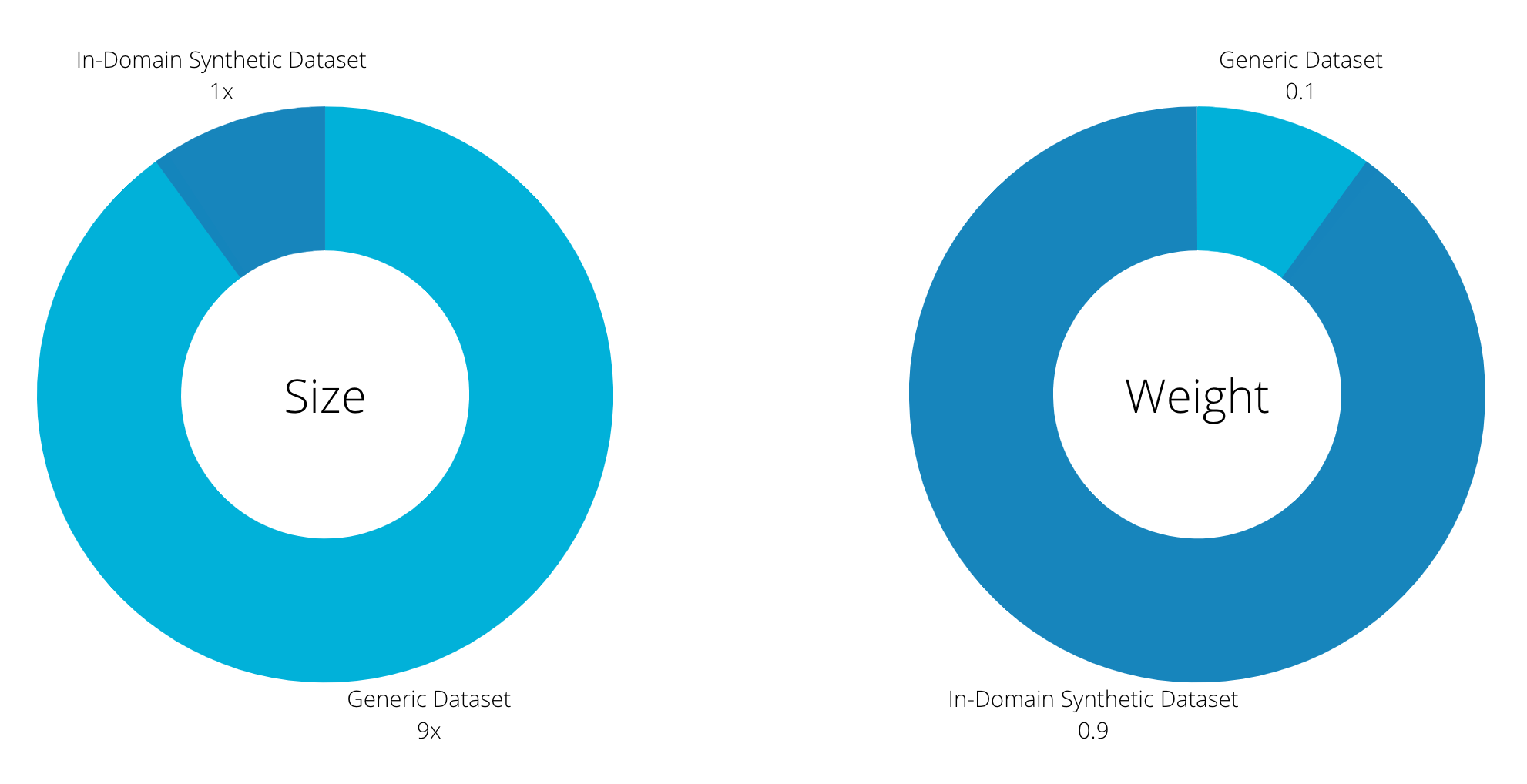
To apply oversampling, we employed the dataset weights feature in OpenNMT-tf. If you are using OpenNMT-py or OpenNMT-tf, you can find more details in this tutorial on mixed fine-tuning of MT models.
Results
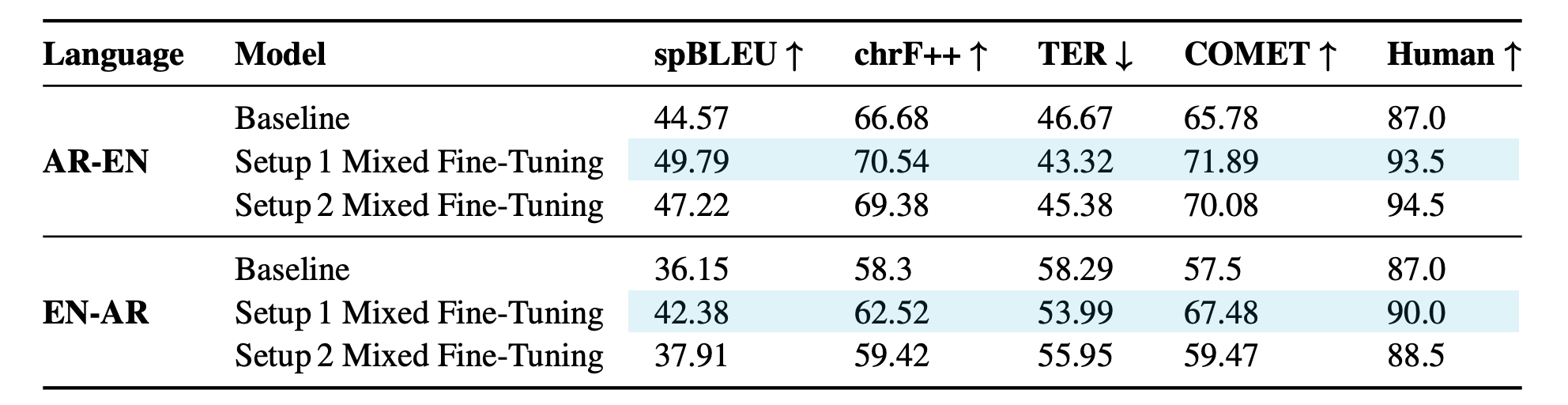
In both scenarios, our proposed method achieves significant improvements, demonstrated by both automatic and human evaluations. As expected, Setup 1 (when there is a tiny bilingual dataset) reveals better results than Setup 2 (where there is no bilingual dataset at all). Still, models resulted from both setups outperform the baseline model.
Conclusion
Previously, synthetic data for machine translation had been created either on the source-side only (forward-translation) or the target side only (back-translation). In some cases, researchers replaced a few words from the source and/or the target with synonyms or similar words. The assumption was that “relevant” monolingual data was available, which was not always the case!
In real-life scenarios, things can get more complex. Usually, there is insufficient human-produced data to train or fine-tune high-quality MT systems. Production-level projects can be so specialised, while mining crawled monolingual datasets is inefficient and not necessarily helpful.
This research work generates brand new synthetic data on both the source and target sides. It employs large language models to put together coherent sentences similar to those to be translated in the current project. Then, the new synthetic data can be used to fine-tune production-level MT systems for domain-specific scenarios. Feel free to check out our paper, Domain-Specific Text Generation for Machine Translation.
Download Scripts
You can download our scripts and configuration files at GitHub. If you have applied the method and/or have questions, please let me know.
Citation
@inproceedings{moslem-etal-2022-domain,
title = "Domain-Specific Text Generation for Machine Translation",
author = "Moslem, Yasmin and
Haque, Rejwanul and
Kelleher, John and
Way, Andy",
booktitle = "Proceedings of the 15th biennial conference of the Association for Machine Translation in the Americas (Volume 1: Research Track)",
month = sep,
year = "2022",
address = "Orlando, USA",
publisher = "Association for Machine Translation in the Americas",
url = "https://aclanthology.org/2022.amta-research.2",
pages = "14--30",
abstract = "Preservation of domain knowledge from the source to target is crucial in any translation workflow. It is common in the translation industry to receive highly specialized projects, where there is hardly any parallel in-domain data. In such scenarios where there is insufficient in-domain data to fine-tune Machine Translation (MT) models, producing translations that are consistent with the relevant context is challenging. In this work, we propose a novel approach to domain adaptation leveraging state-of-the-art pretrained language models (LMs) for domain-specific data augmentation for MT, simulating the domain characteristics of either (a) a small bilingual dataset, or (b) the monolingual source text to be translated. Combining this idea with back-translation, we can generate huge amounts of synthetic bilingual in-domain data for both use cases. For our investigation, we use the state-of-the-art Transformer architecture. We employ mixed fine-tuning to train models that significantly improve translation of in-domain texts. More specifically, in both scenarios, our proposed methods achieve improvements of approximately 5-6 BLEU and 2-3 BLEU, respectively, on the Arabic-to-English and English-to-Arabic language pairs. Furthermore, the outcome of human evaluation corroborates the automatic evaluation results",
}